
What Is Text-to-Video Technology? A Creator's Guide

Stella writes SwipeStory guides about AI faceless video creation, short-form video strategy, creator tools, and automated publishing workflows.
Text-to-video technology is a form of generative artificial intelligence that converts natural language text directly into coherent, temporally consistent video clips. Unlike text-to-image generation, which produces a single frame, text-to-video systems must maintain visual logic across dozens or hundreds of frames simultaneously. That added dimension makes it one of the most technically demanding areas in AI today. For content creators and marketers, the payoff is significant: the ability to convert text to video in minutes, without cameras, crews, or editing software. Swipestory has already used this technology to generate over 60,000 short videos for creators worldwide.
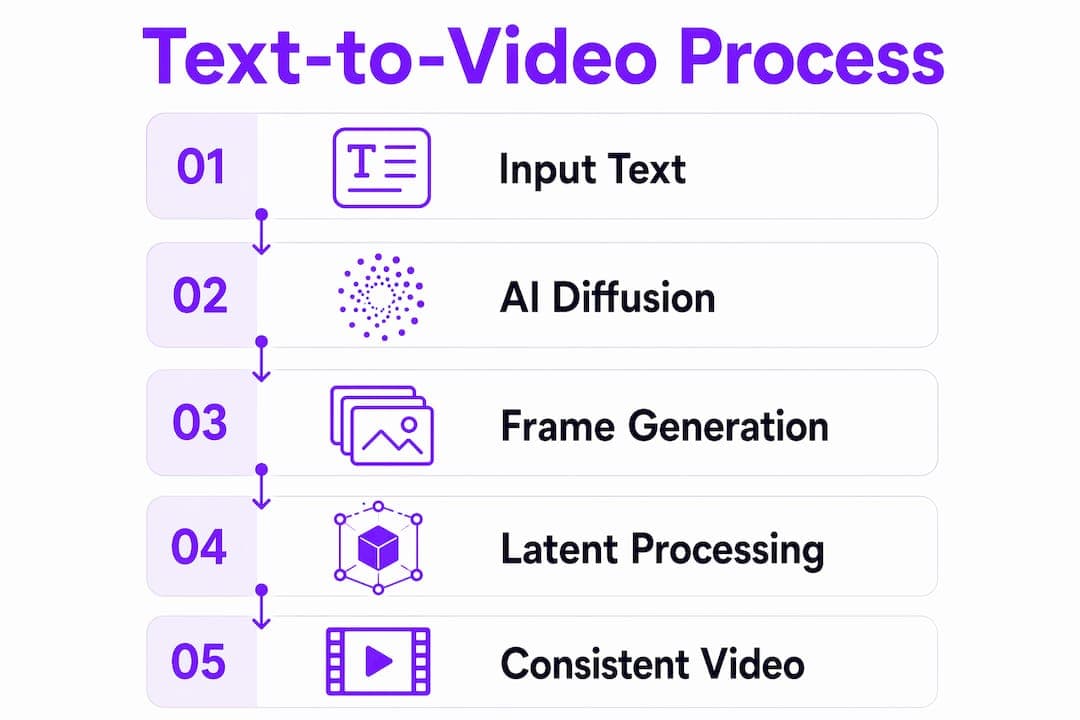
What is text-to-video technology and how does it work?
Text-to-video technology works by running a natural language prompt through a series of AI models that progressively build a sequence of video frames. The process starts the moment you type a description. The system encodes your words into a numerical representation, then uses that representation to guide the generation of every frame in the output.
The core engine behind most modern systems is a diffusion model. Diffusion models start with random visual noise and gradually remove that noise, step by step, until a coherent image or video emerges. Each denoising step is guided by your text prompt through a mechanism called cross-attention. Cross-attention steers generation so the video stays aligned with your intended description at every step, not just at the start.

Processing video at full pixel resolution would be computationally impossible for most hardware. That is why video generation uses latent space through video Variational Autoencoders, or VAEs. A VAE compresses each frame into a compact mathematical representation, runs the diffusion process in that compressed space, then decodes the result back into full-resolution pixels. This compression is what makes real-time or near-real-time generation feasible.
The hardest problem in text-to-video generation is not creating a single good frame. It is keeping every frame consistent with the ones before and after it. Temporal attention mechanisms allow each frame to reference its neighboring frames, enforcing object identity and reducing flicker. Without temporal attention, a character's shirt might change color mid-clip, or a hand might morph between frames.
Pro Tip: Write prompts that describe motion explicitly, not just appearance. "A woman walking briskly through a rain-soaked street" gives the model far more temporal guidance than "a woman on a street."
What are the current capabilities and limitations of text-to-video AI?
Text-to-video AI has advanced rapidly, but knowing exactly what it can and cannot do saves you from wasted effort and misplaced expectations.
What today's systems do well
- Rapid video creation from a single prompt. AI video platforms combine text-to-speech, avatars, and motion synthesis to produce polished clips with minimal manual editing.
- Multi-language support. Leading platforms support localization across more than 130 languages, with some reaching up to 160. That scale makes global content distribution practical for solo creators.
- Avatar-led presentations. AI-generated presenters can deliver scripted content without any filming, which is especially useful for corporate training and explainer videos.
- Resolution up to 1080p. Many platforms now output at full HD, which meets the quality bar for TikTok, Instagram Reels, and YouTube Shorts.
Where the technology still falls short
Computational costs scale exponentially with video length and resolution. That is why most AI-generated clips top out at a few seconds to a couple of minutes. Pushing beyond that requires significantly more processing power, which translates directly into higher costs and longer wait times.
Quality issues remain real. Flickering, motion inaccuracies, and inconsistent lighting across frames are the most common complaints. These problems stem from the challenge of maintaining temporal consistency, which is the agreement between frames in lighting, physics, and object persistence.
The "Will Smith Eating Spaghetti" benchmark has become an informal industry test for model quality. Hand movements and fluid dynamics are notoriously difficult for AI to render convincingly. If a model handles those well, it handles most other motion scenarios well too. Researchers use formal metrics like Inception Score and Fréchet Video Distance to measure output quality more precisely.
High computational costs also mean that significant training data is required for coherent outputs, which limits accessibility for smaller teams or independent developers building their own models.
What are practical applications for content creators and marketers?
Text-to-video applications are widest where speed and volume matter most: social media, marketing, and education.
-
Social media content. A marketer can write a product description and receive a ready-to-post short video for TikTok or Instagram Reels within minutes. Swipestory's social media video maker is built specifically for this workflow, handling script, voiceover, and rendering automatically.
-
Promotional clips. Brands that once needed a production crew for a 30-second ad can now generate multiple variations of the same concept and A/B test them in real time. That kind of iteration was previously reserved for companies with large budgets.
-
Educational explainer videos. Teachers, course creators, and corporate trainers use AI video generation to produce visual explanations of complex topics without screen recording or animation software. An educational video maker powered by AI can turn a lesson outline into a narrated video in one step.
-
Localized content at scale. Because leading platforms support over 130 languages, a single script can produce localized versions for different markets simultaneously. That collapses what used to be a multi-week localization project into a single afternoon.
-
Faceless video content. Creators who prefer not to appear on camera can use faceless video generation to build entire channels without filming a single second of footage. This model is particularly popular for finance, motivation, and educational niches.
AI video tools reduce production times from days to minutes. That is not a marginal improvement. It fundamentally changes what a solo creator or small marketing team can produce in a week.
Pro Tip: Use text-to-video tools to produce draft versions of your content first. Refine the script based on the draft, then regenerate. You will get a better final output than trying to write a perfect prompt on the first attempt.
What should you consider when choosing text-to-video software?
Choosing the right text-to-video software comes down to matching the tool's strengths to your specific content needs. Not every platform handles every use case equally well.
- Supported output formats and platforms. Check whether the tool exports in the aspect ratios and resolutions your platforms require. Vertical 9:16 for TikTok and Reels is different from 16:9 for YouTube. A tool that only exports one format will slow you down.
- Language and localization support. If you create content for international audiences, confirm the number of supported languages and whether the voiceover quality holds up across them. Some platforms offer 160 languages; others offer far fewer.
- Rendering speed and cloud infrastructure. Cloud-based rendering means you are not limited by your laptop's processing power. Swipestory uses cloud rendering, which keeps generation times short regardless of the complexity of your script.
- Prompt and script flexibility. Some platforms accept only short prompts. Others accept full scripts with scene-by-scene instructions. If you want precise creative control, choose a tool that supports script-to-video workflows rather than single-sentence prompts.
- Customization depth. Look for control over captions, visual style, avatar selection, and background music. The more you can customize, the more your output will reflect your brand rather than a generic AI aesthetic.
- Cost structure. Free tiers are useful for testing, but most serious content production requires a paid plan. Evaluate cost per video against your expected monthly output volume before committing.
The most common mistake creators make is choosing a tool based on a single impressive demo. Test the tool with your actual scripts and your actual content categories before deciding.
Key Takeaways
Text-to-video technology converts natural language prompts into video through diffusion models, latent-space processing, and temporal attention, making it the fastest path from written idea to published video content.
| Point | Details |
|---|---|
| Core mechanism | Diffusion models denoise random noise into video frames, guided by your text prompt through cross-attention. |
| Temporal consistency | Temporal attention mechanisms keep objects, lighting, and motion coherent across every frame. |
| Current limitations | Video length and resolution are constrained by computational cost; hand motion and fluid dynamics remain common failure points. |
| Practical value | AI video tools reduce production time from days to minutes, supporting social media, education, and marketing at scale. |
| Tool selection | Match the platform to your output format, language needs, script complexity, and budget before committing. |
Why text-to-video is the workflow shift most creators are underestimating
Most conversations about AI video focus on the output quality. That is the wrong place to look. The real shift is in what becomes possible when the production bottleneck disappears.
I have watched creators go from posting once a week to posting daily, not because they suddenly had more ideas, but because the gap between idea and finished video collapsed from hours to minutes. That change in cadence compounds over time. More content means more data on what resonates, which means better content decisions, which means faster audience growth.
The limitation I see most creators hit is not the technology. It is the prompt. Writing a good video prompt is a skill, and most people treat it like a Google search. The more specific you are about motion, pacing, tone, and visual style, the better the output. Treat your prompt like a director's brief, not a search query.
The temporal consistency problem is real and worth taking seriously. If you need human hands doing something precise, or liquids moving naturally, current AI video generation will frustrate you. Plan your scripts around what the technology handles well: narrated explainers, text-overlay clips, avatar presentations, and abstract visuals. Save the complex physical dynamics for filmed footage.
The creators who will benefit most from this technology are not the ones waiting for perfect AI video. They are the ones building workflows around what AI does well right now, while staying ready to upgrade as the technology improves.
— Jesse
Swipestory's AI video generator for faster content creation
Swipestory automates the full video production process, from script input to voiceover, image generation, and cloud rendering, so you can publish without a production team.
The AI video generator supports multiple formats for TikTok, Instagram, and YouTube, with customizable captions and advanced image generation built in. Creators have already used Swipestory to produce over 60,000 short videos, cutting production time from days to minutes. Whether you are building a faceless channel, producing marketing clips, or scaling educational content, Swipestory gives you a complete text-to-video workflow in one place. Start with the free AI video tools to see what your scripts become.
FAQ
What is text-to-video technology in simple terms?
Text-to-video technology is an AI system that reads a written description and generates a video clip from it. The AI builds each frame using diffusion models and keeps frames consistent through temporal attention mechanisms.
How does text-to-video differ from text-to-image generation?
Text-to-image generates a single frame, while text-to-video must maintain visual consistency across many frames over time. Temporal consistency across lighting, physics, and object identity is the core added challenge.
What are the main limitations of AI video generation today?
Video length and resolution are limited by computational cost, and complex motions like hand articulation and fluid dynamics remain difficult for current models. Significant training data is also required for coherent outputs.
Can text-to-video tools support multiple languages?
Yes. Leading platforms support localization in over 130 languages, with some reaching 160, making it practical to produce content for international audiences from a single script.
What makes a good prompt for text-to-video generation?
A good prompt describes motion, pacing, and visual style explicitly, not just the subject. Specific directional language gives the AI more to work with and produces more consistent, usable output.